(原文出處:https://ericlippert.com/2003/09/12/erics-complete-guide-to-bstr-semantics/)
如果你曾經用 C 或 C++ 寫過任何使用到 COM 物件的程式,你一定看過類似的程式碼:
STDMETHODIMP CFoo:Bar(BSTR bstrABC)
{ ... }這個 BSTR 到底是三小?它和 WCHAR* 又有什麼區別?
像 C 或 C++ 這種低階語言,你有絕對的自由可以決定:究竟要用什麼方式實作某種概念。Unicode 字串就是個絕佳範例。用 C++ 來表示長度為 n 個字元的 Unicode 字串的標準方法是一個指向 2 * (n + 1) bytes 記憶體空間的指標。這塊空間中的前 2 * n bytes 是用來表示 UTF-16 編碼字元的無號短整數 (unsigned short integers),最後 2 個 bytes 的內容則是 0,用來表示字串的結尾。
為了表示上的方便,我們利用「匈牙利表示法」,稱呼這樣的怪物為 PWSZ,意即「指向寬字元的指標,以零結尾 (Pointer to Wide-character String, Zero-terminated)」。以 C++ 的型別系統來說,PWSZ 就是一個 unsigned short *。
COM 儲存字串資料的方法有一點點不同,這種方法和前述的方法類似,以確保用 PWSZ 方式處理字串的程式碼、以及提供 COM 格式字串的程式碼之間,可以良好溝通。不幸的是,這兩者之間的差異並不小。如果你不夠小心,或是不了解這些差異的話,這些細微的差異就會導致令人困擾的錯誤。
COM 的程式碼使用 BSTR 來儲存 Unicode 字串。BSTR 是 "Basic STRing" 的縮寫。之所以這麼命名,是因為這種儲存字串的方法是為了 OLE Automation 開發的,而 OLE Automation 當時又是因為 Visual Basic 語言引擎的開發而開始的。(譯註:所以 BSTR 的 "Basic" 指的就是 "Visual Basic",而不是「基本」。)
從編譯器的角度來看,BSTR 也是一個 unsigned short *。如果你在需要 PWSZ 的地方使用 BSTR,編譯器不會在意,反之亦然。但這並不代表你可以肆無忌憚地這麼做!如果兩者完全一樣,那就不需要分別用不同的名稱表示了。這兩種型別之間有許多不同之處。
在大部份的情況下,BSTR 可以被當成 PWSZ 來使用。但 PWSZ 只有在極少數的情況下,才能被當成 BSTR 來使用。
讓我先列出這兩者之間的區別,同時詳細說明每一點。
- 對於
BSTR,NULL和""在語意上必須完全相同。而對於PWSZ,這兩者的語意通常是不同的。 BSTR物件必須以SysAlloc家族的函式來配置/釋放記憶體。PWSZ物件則可以是 stack 上自動配置的儲存空間,或是使用malloc、new、LocalAlloc或任何其他的記憶體配置函式來配置記憶體。BSTR字串的長度是固定的。PWSZ的長度可以是任意值,只受到其指向的 buffer 的有效記憶體大小限制。BSTR永遠指向 buffer 中的第一個有效字元。PWSZ可能是個指向字串 buffer 中間或結束位址的指標。- 當你配置了 n bytes 給
BSTR時,這個字串可以存放 n/2 個寬字元。當你配置了 n bytes 給PWSZ時,你可以存放 n / 2 - 1 個字元,因為你必須保留最後一個字元的空間存放表示結尾的零字元。 BSTR宇串中可能包含任何的 Unicode 資料,包括零字元。PWSZ除了結尾的 零字元以外,不得包含任何的零字元。不管是BSTR還是PWSZ,在最後一個有效字元的後面,都會有一個零字元;但是在BSTR中,零字元也可以是有效字元。BSTR的 byte 長度其實可以是奇數 -- 它可以用來傳遞二進位資料,雖然我不建議這麼做。PWSZ的 byte 長度則一定是偶數,而且只能用來儲存 Unicode 字串。
多年來,我發現、修復了無數的錯誤,都是因為程式碼原作者假設 PWSZ 可以當作 BSTR(或反過來)使用,進而違反了上述的差異之一。讓我們仔細來討論這些差異吧:
-
如果你寫的函式接受一個型別為
BSTR的參數,那麼你就必須接受NULL是個有效的BSTR字串,而且把它視為指向空字串(即長度為 0 的字串)的指標。COM 照著這個規則走,而且 Visual Basic 和 VBScript 也是如此。所以如果你想跟別人一起玩,你就得遵守這個遊戲規則。如果 VB 中的某個字串變數恰好是空字串,那麼 VB 傳進來的參數就有可能是NULL,也有可能是指向空字串的指標 -- 完全視該 VB 程式的內部處理方式而定。對於使用PWSZ的程式碼來說,通常不是這樣的:通常NULL指的是「這個字串值不存在」,而不是等同於空字串。
在 COM 中,如果你有一個「可能存在、也可能不存在」的資料,那麼你應該要用VARIANT來儲存,然後用VT_NULL代表數字不存在;而不是將NULL解譯為空字串以外的意義。 -
BSTR字串必須要使用SysAllocString、SysAllocStringLen、SysFreeString等函式來分配、釋放記憶體。底層的記憶體是由作業系統快取的,若是對BSTR使用free或是delete會造成 heap 損毀的嚴重錯誤。同理,使用malloc或new來配置 buffer 空間、再指派給BSTR物件,也一樣會造成錯誤。作業系統內部的程式碼對BSTR在記憶體中的佈局做了假設,嘗試去模擬這樣的佈局是不智之舉。相對來說,PWSZ則可以使用任何的分配方式來配置記憶體,也可以直接配置在 stack 空間中。 -
在
BSTR中,字元的數量是固定的。一個長度為 10 bytes 的BSTR,裡面包含了 5 個 UTF-16 的字元,就這樣。就算這些字元都是 0,它還是包含了 5 個 零字元。另一方面,PWSZ可以包含「不超過 buffer 大小」的字元數:WCHAR pwszBuf[101]; pwszBuf[0] = 'X'; pwszBuf[1] = '';現在
pwszBuf是個包含有一個字元的字串,而且可以最多增長到 100 個字元,或是縮短成 0 個字元的空字串。 -
BSTR指標永遠指向 buffer 中的第一個有效字元。下面這樣做是不合法的:BSTR bstrName = SysAllocString(L"John Doe"); BSTR bstrLast = &bstrName[5]; // 錯誤bstrLast不是合法的BSTR。但對PWSZ來說,這麼做是完全合法的:WCHAR * pwszName = L"John Doe"; WCHAR * pwszLast = &pwszName[5]; -
請參照 (6)。
-
當你了解
BSTR在記憶體中的佈局到底是怎樣之後,就能更清楚為什麼會有上述的那些限制,同時也能解釋為什麼配置了 n 個字元的BSTR可以存放 n 個字元,而不是像PWSZ一樣只能放 n - 1 個字元。當你呼叫SysAllocString(L"ABCDE")時,作業系統其實會幫你配置 16 bytes 的空間。最前面的 4 bytes 是一個 32-bit 的整數,用來表示「這個字串中的有效 bytes 數量」 -- 在這個例子中會被填入 10。接下來的 10 個 bytes 的所有權屬於呼叫者,而內容則會是透過配置函式傳入的資料。最後的兩個 bytes 會被填入 0。然後你會得到一個指向資料(而非標頭)的指標。(譯註:示意圖如下)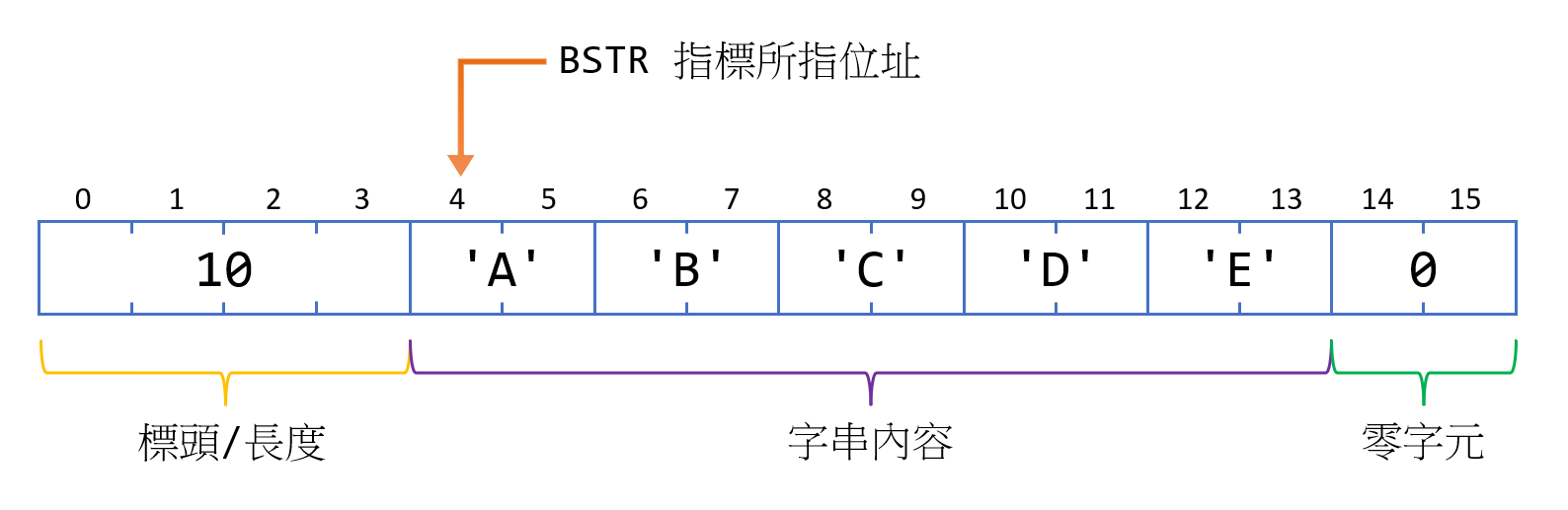
這立刻解釋了幾個關於
BSTR的事實:- 字串長度可以立刻得知。
SysStringLen並不會像wcslen一樣一個字元一個字元算到零字元。它可以直接讀取指標前面的整數,立刻回傳。 - 這也是為什麼
BSTR指標不可以指向另一個BSTR字串中間的任意一個字元。因為這個指標的前面不會是字串的長度。 BSTR可以被當成PWSZ使用,因為配置函式一定會幫你在字串的結尾加上一個零字元。身為呼叫者的你,不需要擔心是否配置了足夠放置零字元的記憶體。如果你需要 5 個字元長的字串,直接跟配置函式要求 5 個字元就好。- 這也是為什麼
BSTR必須使用SysAlloc系列的函式來配置/釋放。只有這函式才能完全了解這些幕後的細節。
- 字串長度可以立刻得知。
-
因為
BSTR的 bytes 長度是已知的,所以不需要使用「零字元代表字串結束」這樣的慣例。因此,在BSTR中,零字元是合法的字元。這表示BSTR可以包含任意的資料,表括二進制映像資料。因為這個原因,BSTR除了可以處理字串資料外,還常被當成一種處理二進位資料的方便方法。這意味著在某些特殊的情況下,它的長度可能會是奇數。這種情況很少見,但不是完全不可能發生,你得特別注意。我建議不要這麼做,但你還是有可能碰到。
呼,終於!總結來說,這應該可以解釋為什麼 BSTR 通常可以當成 PWSZ 使用,但 PWSZ 卻不能當做 BSTR 來用,除非它真的是 BSTR。BSTR 只有在下面這些情況下才 不能 被當成 PWSZ 使用:
- 當
BSTR為NULL時 - 當
BSTR的內容中有零字元時(因為處理PWSZ的程式碼會把零字元當成字串結尾,導致程式會認為字串長度比實際上的短) - 當
BSTR所包含的其實不是字串,是二進位資料時
唯一一個可以把 PWSZ 當成 BSTR 使用的情況,就是那個 PWSZ 其實 就是 BSTR,而且經過正確的配置程式配置空間。
在我自己寫的 C++ 程式碼中,我會很小心地使用匈牙利命名法,記錄指標所指向的資料為何,以避免不必要的誤解。使用匈牙利命名法時,要能捕捉到變數的語意資訊,才會有最好的效果。以下是我使用的慣例:
bstr:真正的BSTRpwsz:指向「以零字元結尾」的寬字元字串的指標psz:指向「以零字元結尾」的窄字元字串的指標ch:字元pch:指向一個寬字元的指標cch:字元個數b:一個 bytepb:指向一個 byte 的指標cb:byte 個數